One of the things I love most about my field (Communication) is its unique passion for building corpora. While there is an obvious value to studying a large, well-studied, pre-structured corpora like LOB or COCA (e.g., multiple scholars working on one dataset increases knowledge about that dataset, reproducibility, etc.), some research questions require more specialized text data.
This is often the situation that I find myself in. If I want to study a linguistic phenomenon in a specific register—like the use of “a thing” in English tweets—I usually have to build my own corpus. So how does one do that?
I’ll break my process down into four broad steps: (1) armchair linguistic-ing, (2) creating the corpus, (3) finding your linguistic phenomenon, (4) corpus analysis.
01. Armchair Linguistic-ing
I became primarily interested in this construction because of its frequency in language use. In spoken English, sentences like, “oh yeah, that’s a thing” are commonplace, even in formal-ish settings, like classrooms (I’m in a J-School, so it’s not unusual to hear someone say, “Yeah, AP style is a thing”).
I’ve always liked this construction, because “a” and “thing” are particularly vague English words. The determiner “a” (as in “I gave her a book”) is indefinite, meaning it refers to something non-specific (contrast this to “I gave her the book”). And “thing” is so broad, it could refer to any tangible, inanimate object. A watch, a book, a stroller, a ticket to Disney—all of these things are things. But when we put “a thing” together, it can suddenly take on a whole new meaning. When someone says, “AP style is a thing”, they mean “people know about AP style” or “AP style is popular”. In this context, the “a thing” is more than an indefinite determiner and a vague noun. Rather, it signifies some degree of importance.
But is this always the case? I wasn’t sure. So, I turned to my corpus building skills to find out.
I figured there could be four general places that “a thing” could be situated in. The first is the subject, like in the sentences below:
A thing needs to be done.
A thing just arrived.
The second possibility is in the object position, such as in the examples below:
I know a thing or two about school.
I made a thing.
It is also possible that “a thing” is used as a predicate noun/nominative. It is also a subject complement, because it completes a linking verb (in English, “to be”). This is the structure I was most interested in.
This is a thing.
That has been a thing for a long time.
And finally, we’ll look into object complements, such as in the examples below:
He considered the party a thing.
He cooked his friends a thing.
Now that I knew what I was looking for, it was time to build and parse my corpus.
02. Building Your Corpus
The first thing you’ll need to think about is where you want to get the data from. Do you want to look at journal articles? Fiction novels? Text messages between friends?
I settled on Twitter for a few reasons, the most important of which was “it is an informal register that is easy to get.” I figured the feature I was looking for would likely not be in a formal register, like news stories or presidential speeches. However, Twitter (and social media language as a whole) is simultaneously beautiful and frustrating in its kind-of-formal, kind-of-informal language norms (beautiful in that language evolves so quickly, frustrating in that there are way too many people who use prescriptivism to put down other people’s tweets).
If you are trying to access the Twitter RestAPI through R, I strongly advocate using rtweet, by Mike Kearney. It’s a really cool package, and a great way to build interesting Twitter corpora at your leisure.
library(rtweet)
#?search_tweets
rstats_tweets <- search_tweets(q = '"a thing"',
n = 1000000,
retryonratelimit = TRUE) #max 18,000 every 15 minutes
head(rstats_tweets, n = 5) #looks at the top 2 tweetsThis search yielded about 500,000 tweets (510,574, to be exact). To identify whether the bigram “a thing” would be used as a subject, object, predicate, or object complement, I would need to annotate this bad boy.
Right now, I’m using the R clearNLP package, with back ends to spaCy and CoreNLP. I tend to use the latter more (coreNLP) because I’ve gotten better results. But spaCy is much faster and has additional support. I strongly encourage it for those who are both R and Python-proficient (it can also support word vectors and has a great displaCy visualizer).
library(rJava)
library(tokenizers)
library(cleanNLP)In order to use cleanNLP, you’ll need to interface with the back end (either coreNLP or spaCy).
#cnlp_init_tokenizers() #initializes tokenizer backend
cnlp_download_corenlp()
cnlp_init_corenlp("en", anno_level = 2)
# cnlp_init_spacyOnce you have done this, you are ready to parse your corpus! For the purposes of this exercise, I’m going to use some toy data (parsing the full corpus took about 2 days—I had about 20 million dependencies total).
Toy Data
If you notice, 8 of the 9 sentences are the ones in my previous examples.
toy_data <- data.frame(id = c("s1", "s2", "o1", "o2", "sp1", "sp2", "sp3", "dc1", "dc2"),
sentence = c("A thing needs to be done.", "A thing just arrived.",
"I know a thing or two about school.",
"I made a thing.",
"This is a thing.",
"Is summer camp a thing?",
"That has been a thing for so long.",
"He considered the party a thing.",
"He made his friends a thing."))starttime <- Sys.time()
full_corpus_dep <- toy_data$sentence %>% as.character() %>%
cnlp_annotate(as_strings = TRUE, doc_ids = toy_data$id) %>%
cnlp_get_dependency(get_token = TRUE)
endtime <- Sys.time()
You want to make sure that you indicate the doc_ids of the data, as that is what you will use to re-align the dependency information to the original tweet or sentence.
Once you do this, you should get a data frame that looks something like this:
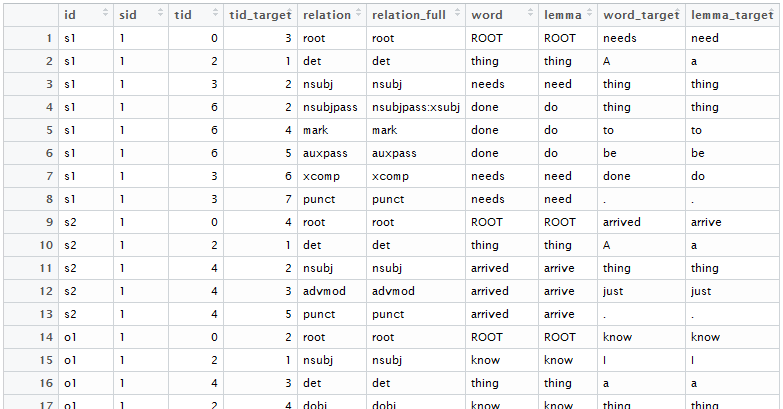
Let’s break what cnlp_get_dependency produces. Each row represents one dependency relationship. Each column represents some information about that dependency (e.g., what document or sentence the dependency is in, what words the dependency relationship is linking, etc.)
A brief interlude to help us understand dependency grammar… Dependency grammar interprets two words as having a dependency (relationship) between them. This differs from constituency grammar, which breaks down word relationship into phrases, not dependencies. An important skillset in this work is being able to read the results of one and interpret it as the other (e.g., see dependency relations and conceptualize them as phrases, or see phrases and construct the dependencies).
Because dependencies focus on relationship between two words, we can conceive of a dependency relationship as having a “word”, a “wordtarget”, and a “relation”. Consider the very simple example of “I run.” In this sentence, we have a subject and a verb. In dependency grammar, the verb is the “root” or the center of the sentence. Therefore, each of your sentences will usually have a root. Arrows lead out from the root to other words (these are the “word targets”). Thus, if “run” is the root verb, then the word target “I” is the subject to that verb.
Let’s now look at each column in more detail. The <id> is pretty obvious: it’s the document id, or <doc_ids>, you indicated previously. The <sid> is the sentence number. For most tweets and sentences, the <sid> number will be a 1. However, blog posts, news articles, products reviews, and other longer documents are all likely to have multiple sentences. The <tid> refers to the token number of the word. There is also a <tid_target>, which is the token number of the word target.
The six other columns are: <relation>, <relation_full>, <word>, <lemma>, <word_target>, and <lemma_target>. The <lemma> and <lemma_target> are the lemmatized forms of the word and word_target (for example, the words “thinking”, “thought”, and “thinks” can be represented by the lemma /think/. Using the lemmatized form meant I largely did not have to worry about tense issues.
The <relation>, <word>, and <word_target> are the meat of the dependency analysis. The first “dependency” of a sentence is usually the ROOT verb. Let’s return to our “I run.” Example below.

As you can see, the “run” verb is identified as the root. This is not really a dependency, but more an identification of what the root verb is (hence why there is no actual <word>, and why the <tid> is 0). The second row identifies a <nsubj> dependency “relation”, with the root verb “run” as the <word>, and the noun subject “I” as the <word_target>.
There are many (many) possible dependency relations. You can find a list of them here.
There is some older documentation that can also be potentially useful here (this version of the dependencies is no longer maintained).
Let’s now apply this knowledge to our toy data.
03. Finding your Linguistic Phenomenon
Recall that our goal is to identify whether the bigram “a thing” appears as a subject, object, predicate, or object complement.
Let’s do so by identifying all the dependencies for which “thing” is a <word> or <word_target> (the “a” in “a thing” will be identified as a determiner <word_target> to the “thing”).
thing_word <- subset(full_corpus_dep, word == "thing")
thing_target <- subset(full_corpus_dep, word_target == "thing")
Notice that the “a thing” dependency shows up in the <thing_word> subsetted data. But the more useful dataset for us is the <thing_target> data.
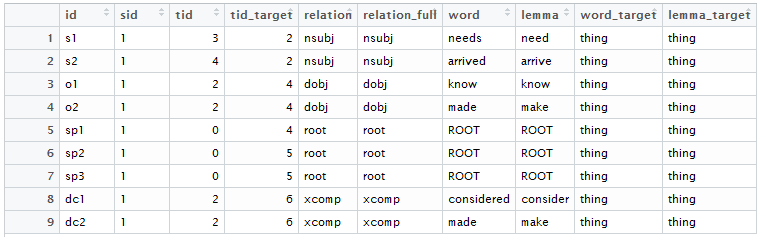
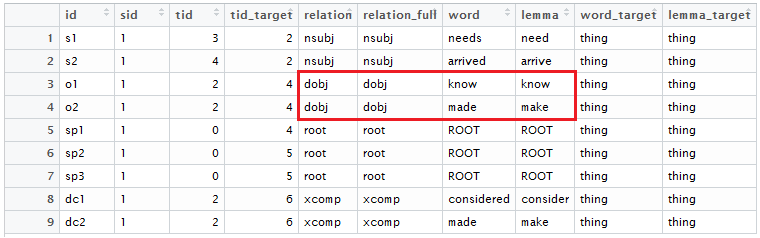
Notice that, if in the subject position, the “thing” <word_target> has a <nsubj> (noun subject) <relation> to a verb. In the object position, the “thing” <word_target> has a <dobj> (direct object) <relation>. In the predicate position, the “thing” <word_target> is the ROOT (if you check the <word> data, you will also note a <cop>, or copula, <relation> from the verb “to be” to the “thing” <word>). In the object complement position, the “thing” <word_target> has an <xcomp>, or an “open clausal complement” <relation>.
Below is an image of all the dependency relationships I was interested in, as related to the “a thing” bigram.
Side note: While the toy data plays nicely, real data isn’t always perfectly parsed. For example, I had about 2,000 tweets where a copula-predicate relationship was identified as a subject-verb(“to be”)-object relationship (these had a “nsubj” + “det” + “dobj” relationship, but the root lemma was “be”—this meant they were initially coded as “objects” but, upon further examination, I subset them to the predicate list).
04. Corpus Analysis
Now that we know what the relationships are, we can re-aggregate to the tweet level. My corpus had a few instances (<10) where “a thing” was used twice. In all these instances, however, the “a thing” bigrams were in the same position.
subject <- subset(thing_target, relation == "nsubj", select=id) %>% mutate(subject = 1)
object <- subset(thing_target, relation == "dobj", select=id) %>% mutate(object = 1)
predicate <- subset(thing_target, relation == "root", select=id) %>% mutate(predicate = 1)
complement <- subset(thing_target, relation == "xcomp", select=id) %>% mutate(complement = 1)
toy_data2 <- merge(toy_data, subject, by = "id", all.x = T) %>%
merge(object, by = "id", all.x = T) %>%
merge(predicate, by = "id", all.x = T) %>%
merge(complement, by = "id", all.x = T)
toy_data2[is.na(toy_data2)] <- 0
Let us now turn to the results of the full data.
Results

As we can see, the bigram “a thing” is most likely to appear in the object position (“I made a thing”) or predicate position (“This is a thing“).Rarely is “a thing” used in the subject position (e.g., “Love the phrase ‘a meteoric rise’, a thing a meteor has never done”). Fewer than 250 tweets had “a thing” in the object complement position.
“A thing” in the Predicate position
As I expected, tweets that used “a thing” in the predicate noun position discussed a subject as popular, socially important, or at least well-known. These tweets usually followed a similar structure: the word “thing” is the root. The word_target “a” is a determiner to “thing”, and the lemma “to be” (representing “is”, “are”, “was”, and “were”) is a copula to “thing”. Finally, the “nsubj” relationship would link the noun word_target to the “thing” word (this is why we need the thing_word subsetted data).

So what are nouns are described as “a thing”?
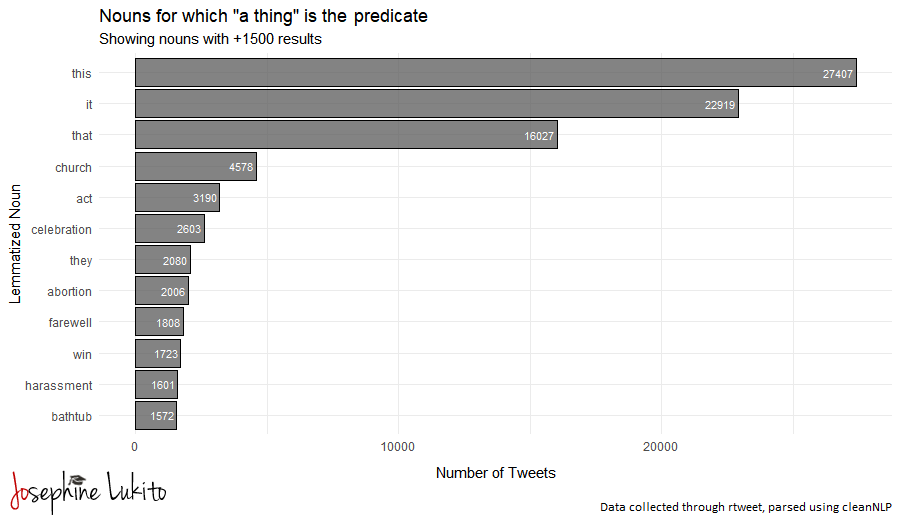
The figure above shows that, when "a thing" is a predicate, it often link to demonstrative determiners (this, that) or the pronoun "it". We also see some more specific nouns, such as ‘church”, “abortion”, and “harassment”.
Many of these tweets were exclamations (e.g., “I didn’t know this was a thing!” or “OMG this is a thing?!” or “Had no idea this was a thing!!”). Some were questions, about whether something was “still a thing”: “I grew up being told about thick and thin. Is that still a thing[?]”
“Church” appeared often in tweets like, “Is church still a thing?” and “How is church and religion still a thing?” In at least one instance, a tweet was incorrectly parsed: “separation of church and state is a thing, you know that right little @mike_pense?” (the parser coded this as ([NP] separation ([PP]of ([N] church)) ([CONJ] and) ([N] state), rather than treating “church and state” as a conjunction within the preposition phrase).
Many people also described abortions as a thing (or not a thing). A few tweets noted “Abortions are a thing” to note the frequency with which they occur. One tweet said “Late term abortions should not be a thing”, focusing on a specific type of abortions. Another said, “Post-term abortion is not a thing”, referring specifically to President Trump’s coinage.
“A thing” in the object position
Let us now turn to the use of “a thing” in the object position. In these cases, “a thing” is still relatively vague. If you “make a thing”, you’re not necessarily saying the thing you made is popular or well-known—you may simply be happy that you did it (e.g., “I did a thing!”).We can explore this structure more by looking at the verbs associated with the “a thing” bigram in the object position. The dependency relationship would be a dobj from the word_target “a thing” to a verb.
The figure below displays the verbs that appeared at least 5000+ tweets, for which “a thing” was a direct object.

Keep in mind that these verbs are lemmatized (therefore the lemma “know” represents “know” and “knew”). By far, the most common verbs used were “to do” and “to make” (as in “I did a thing” and “I made a thing”). This is followed by “to have”, “to know”, “to miss”, and “to learn”.
For example, one tweet said “I made a thing for Pokemon fans and Kingdom Hearts fans [Image]”. Note that the author provided additional info (a prepositional phrase and an image) to describe the “thing”. Another user tweeted, “It looks bad but i did a thing [image].” Many of these tweets expressed some pride over doing, making, creating, having, buying, or owning “a thing”. This was almost always accompanied by pictures of what the “thing” was.
Some tweets also referenced love, as in “love don’t mean a thing” or “love don’t cost a thing”. About 6000 tweets used the verb “change”, and were often about commenting on other people’s worth (e.g., “don’t change a thing!”)
Overall, I really enjoyed doing this analysis. It’s been more difficult to do this analysis with my Ph.D work picking up, but I’m glad I can still find the time every now and again.